现在是成为数据科学家的好时机. 如果你把话题转向“大数据”,严肃的人可能会对你感兴趣。, 当你提到“人工智能”和“机器学习”时,派对上的其他人会很感兴趣. 甚至 谷歌认为 你不坏,而且你正在变得更好. 有很多“智能”算法可以帮助数据科学家施展他们的魔法. 这一切可能看起来很复杂, 但是如果我们稍微理解和组织一下算法, 找到并应用我们需要的那个并不难.
关于数据挖掘或机器学习的课程通常会从 聚类,因为它既简单又有用. 它是一个更广泛的无监督学习领域的重要组成部分, 我们想要描述的数据哪里没有标记. 在大多数情况下,这是用户没有给我们太多关于预期输出的信息. 算法只有数据,它应该尽其所能. 在我们的例子中, 它应该执行聚类——将数据分成包含相似数据点的组(簇), 而组与组之间的差异则尽可能的高. 数据点可以代表任何东西,比如我们的客户. 如果我们, 例如, 希望对相似的用户进行分组,然后在每个集群上运行不同的营销活动.
经过必要的介绍, Data Mining courses always continue with k - means; an effective, 广泛使用的, 全方位聚类算法. 在实际运行之前, 我们必须定义数据点之间的距离函数(例如, 欧几里得距离,如果我们想在空间中聚集点的话), 我们需要设定我们想要的簇数(k).
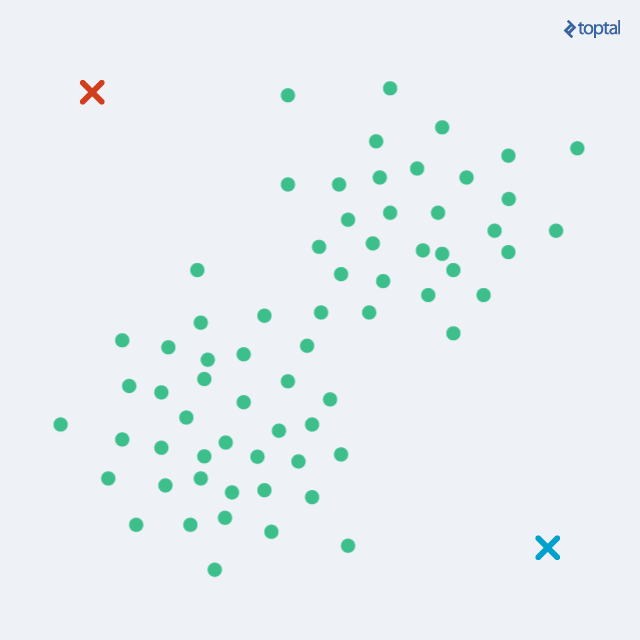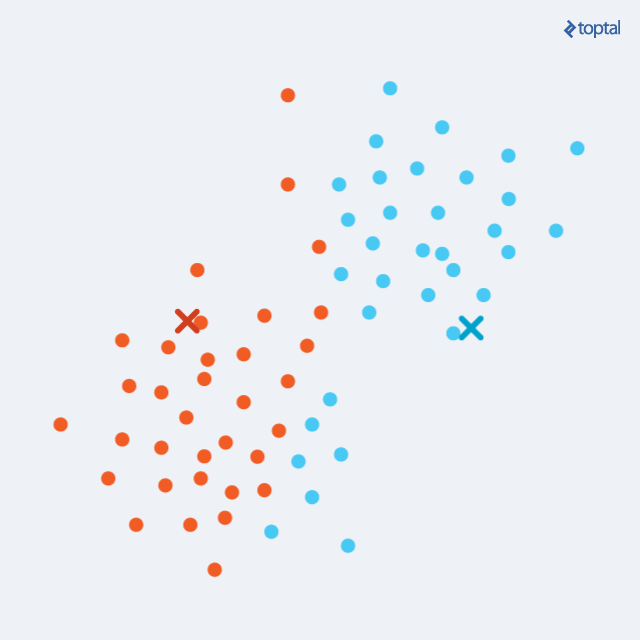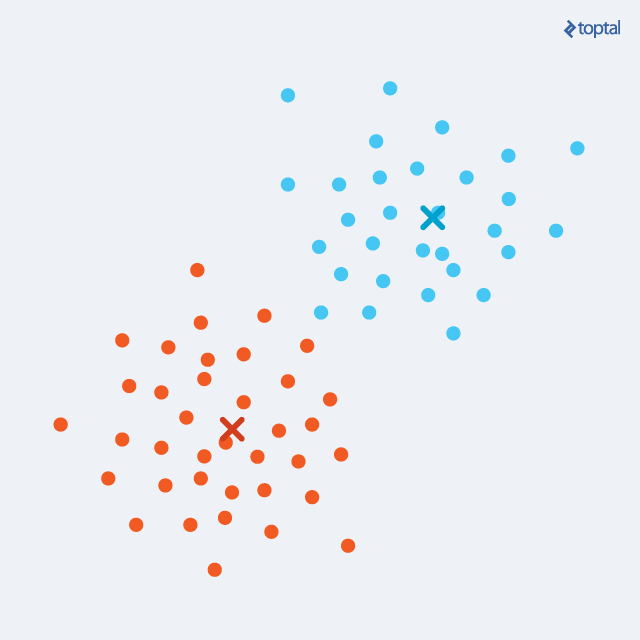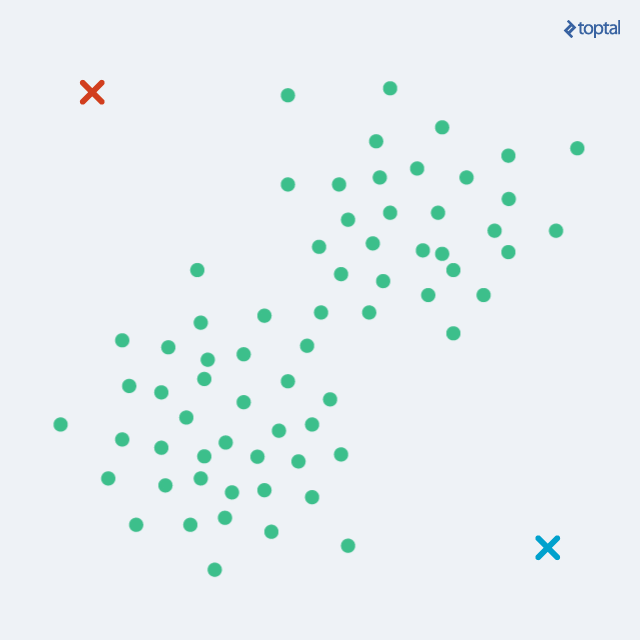
算法首先选择k个点作为起始质心(聚类的“中心”)。. 我们可以随机选择k个点, 或者我们可以用其他方法, 但是随机选择点是一个好的开始. 然后,我们迭代地重复两个步骤:
分配步骤:我们数据集中的m个点中的每一个都被分配到一个聚类中,该聚类由k个质心中最近的一个表示. 对于每个点,我们计算到每个质心的距离,并简单地选择距离最小的一个.
更新步骤:对于每个聚类,计算一个新的质心作为聚类中所有点的平均值. 从前面的步骤中,我们有一组点被分配给一个集群. 现在,对于每一个这样的集合,我们计算一个均值,我们声明一个新的聚类质心.
每次迭代之后, 质心在缓慢移动, 每个点到其指定质心的总距离变得越来越小. 这两个步骤是交替进行的 直到收敛这意味着直到集群分配没有更多的变化. 经过多次迭代, 将为每个质心分配相同的点集, 因此又回到了相同的质心. k - means保证收敛于局部最优. 然而,这并不一定是最好的整体解决方案(全局最优).
最终的聚类结果取决于初始质心的选择, 所以人们对这个问题进行了很多思考. 一个简单的解决方案就是用随机初始赋值运行k - means几次. 然后,我们可以通过从每个点到其集群的距离总和最小来选择最佳结果-我们首先试图最小化的误差值.
其他选择初始点的方法可以依赖于选择远点. 这可以带来更好的结果, 但我们可能会遇到异常值的问题, 那些罕见的“关闭”的单独点可能只是一些错误. 由于它们远离任何有意义的集群,每个这样的点可能最终成为自己的“集群”。. 一个好的平衡是 k - means + + 变体[亚瑟和瓦西尔维茨基, 2007], 它的初始化仍然是随机选取点, 但概率与先前分配的质心的平方距离成正比. 越远的点越有可能被选为起始质心. 因此, 如果有一组点, 组中某点被选中的概率也会随着概率的增加而增加, 解决了我们提到的离群值问题.
k - means++也是Python的默认初始化 Scikit-learn k - means实现. 如果您正在使用Python,那么这个库可能是您的首选. 对于Java, Weka 图书馆可能是一个好的开始:
//加载一些数据
Instances data =数据源.读取(“数据.飞机救援消防”);
//创建模型
SimpleKMeans = new SimpleKMeans();
//我们需要三个集群
kMeans.setNumClusters (3);
//运行k - means
kMeans.buildClusterer(数据);
//打印质心
Instances centroids = kMeans.getClusterCentroids ();
for(实例质心:质心){
系统.出.println(重心);
}
//打印每个实例的集群成员
for(实例点:data) {
系统.出.println(点+ " is in cluster " + kMeans.clusterInstance(点));
}
> >> from sklearn import cluster, datasets
> >> iris = datasets.loadiris ()
> >> Xiris = iris.data
> >> yiris = iris.目标
> >> kmeans = cluster.KMeans (nclusters = 3)
> >> kmeans.适合(Xiris)
KMeans (copy_x = True, init =“k - means + +”, ...
> >> print(kmeans.标签[::10])
[1 1 1 1 1 0 0 0 0 0 2 2 2 2 2]
> >> print(yiris[::10])
[0 0 0 0 0 1 1 1 1 1 2 2 2 2 2]
在上面的Python示例中, 我们使用了一个标准的示例数据集“虹膜”, 哪一个包含了三种不同种类鸢尾的花瓣和萼片尺寸. 我们把它们分成三组, 并将获得的群集与实际物种(目标)进行比较, 看它们是否完美匹配.
在这种情况下, 我们知道有三种不同的群集(物种), k - means可以正确地识别出哪些是一起出现的. 但是,我们如何选择合适数量的聚类k? 这类问题在机器学习中很常见. 如果我们请求更多的集群, 它们会更小, 因此,总误差(从点到指定簇的总距离)会更小. 那么,设置一个更大的k是不是一个好主意? 我们可以得到k = m, 这是, 每个点都是它自己的质心, 每个集群只有一个点. 是的, 总误差为0, 但我们没有得到更简单的数据描述, 它也不足以涵盖可能出现的一些新问题. 这叫做过拟合,我们不希望那样.
处理此问题的一种方法是对较多的集群添加一些惩罚. 所以,我们现在不仅要最小化误差,还要 错误+处罚. 当我们增加簇的数量时误差会收敛于零, 但惩罚将会加大. 在某些时候, 增加另一个集群的收益将小于引入的损失, 我们会得到最优的结果. 一个解决方案使用 贝叶斯信息准则 (BIC)被称为X-Means [Pelleg and Moore, 2000].
我们要定义的另一个东西是距离函数. 有时,这是一项简单的任务,根据数据的性质,这是一项合乎逻辑的任务. 对于空间中的点, 欧几里得距离是一个明显的解, 但对于不同“单位”的特征来说,这可能会很棘手, 对于离散变量, 等. 这可能需要大量的领域知识. 或者,我们可以向机器学习寻求帮助. 我们可以试着学习距离函数. 如果我们有一个训练集的点,我们知道他们应该如何分组(i.e. 用它们的聚类标记的点), 我们可以使用监督学习技术来找到一个好的函数, 然后将它应用到尚未聚类的目标集.
在k - means中使用的方法,其两个交替的步骤类似于一个 采用 (EM)方法. 实际上,它可以被认为是EM的一个非常简单的版本. 然而, 它不应该与更复杂的EM聚类算法混淆,尽管它们有一些相同的原理.
So, 使用k - means聚类,每个点只分配给一个单独的聚类, 一个星团只能用它的质心来描述. 这不是很灵活, 因为我们可能会遇到重叠集群的问题, 或者不是圆形的. 与 EM聚类, 现在我们可以更进一步,用质心(均值)来描述每个簇。, 协方差(所以我们可以有椭圆簇), 权重(簇的大小). 一个点属于一个簇的概率现在由一个多元高斯概率分布给出(多元-取决于多个变量). 这也意味着我们可以计算一个点在高斯钟形曲线i下的概率.e. 一个点属于一个簇的概率.

我们现在通过计算开始EM程序, 对于每个点, 它属于当前每一个簇(其中, 再一次。, 可能是在开始时随机创建的). 这是e步. 如果一个集群是一个非常好的候选点,它的概率将接近于1. 然而, 两个或更多的集群可以是可接受的候选者, 所以这个点在集群上有一个概率分布. 这个算法的性质, 不属于一个聚类的点被称为“软聚类”.
m步现在重新计算每个集群的参数, 使用前一组聚类的点分配. 来计算新的平均值, 聚类的协方差和权重, 每个点数据由其属于聚类的概率加权, 如前一步所计算的.
交替这两个步骤将增加总对数似然,直到收敛. 同样,最大值可能是局部的,因此我们可以多次运行该算法以获得更好的聚类.
如果我们现在想为每个点确定一个簇, 我们可以简单地选择最可能的那个. 有一个概率模型, 我们也可以用它来生成类似的数据, 那就是对更多与我们观察到的数据相似的点进行抽样.
亲和力传播 (AP)于2007年由Frey和Dueck出版, 由于它的简单,它越来越受欢迎, 具有普遍适用性, 和性能. 它的地位正在从最先进的技术转变为事实上的标准.

k - means和类似算法的主要缺点是必须选择簇的数量, 然后选择初始点集. 亲和力传播, 而不是, 将数据点对之间的相似性作为输入度量, 并同时考虑所有数据点作为潜在的范例. 实值消息在数据点之间交换,直到一组高质量的示例和相应的聚类逐渐出现.
作为输入,算法需要我们提供两组数据:
数据点之间的相似性, 代表一个点是多么适合成为另一个点的范例. 如果两点之间没有相似性, 因为它们不可能属于同一个集群, 根据实现的不同,这种相似性可以省略或设置为-Infinity.
首选项,表示每个数据点作为范例的适用性. 我们可能有一些先验的信息哪些点适合这个角色, 所以我们可以用偏好来表示.
相似性和偏好通常通过单个矩阵表示, 主对角线上的值在哪里表示偏好. 矩阵表示适合于密集数据集. 点之间的连接是稀疏的, 不把整个n × n矩阵存储在内存中更实用, 而是保留一个相似点与连接点的列表. 幕后, “在点之间交换信息”和处理矩阵是一样的, 这只是一个观点和实施的问题.

然后,该算法进行多次迭代,直到收敛. 每次迭代有两个消息传递步骤:
计算责任:责任r(i), K)反映了累积的证据,证明K点是多么适合作为I点的范例, 考虑到第一点的其他潜在例子. 责任从数据点i传递到候选范例点k.
计算可用性:可用性a(i), K)反映了累积的证据,证明点I选择点K作为其范例是多么合适, 考虑到其他点的支持,k点应该是一个范例. 可用性从候选范例点k发送到点i.
为了计算责任, 该算法使用前一次迭代计算的原始相似度和可用性, 所有可用性设置为零). 责任设置为点i和点k之间的输入相似度作为其范例, 减去点I和其他候选样例之间的相似性和可用性总和的最大值. 计算一个点对一个范例的适合程度背后的逻辑是,如果初始的先验偏好更高,它就更受青睐, 但是,当有一个类似的点认为自己是一个好的候选人时,责任就会降低, 所以两者之间存在“竞争”,直到其中一个在某些迭代中被决定.
可用性计算, 然后, 使用计算的责任作为每个候选人是否会成为一个好的榜样的证据. 可用性(我, K)设为自责任r(K, K)加上候选范例K从其他点获得的积极责任的总和.
最后, 我们可以有不同的停止标准来终止这个过程, 例如当值的变化低于某个阈值时, 或者达到最大迭代次数. 在任何时候通过亲和传播过程, 责任矩阵(r)和可用性矩阵(a)的总和给出了我们需要的聚类信息:对于点i, 最大r(i)的k, K) + a(i, K)表示点i的样例. 或者,如果我们只需要样本集,我们可以扫描主对角线. If r(i, i) + a(i, i) > 0, point i is an exemplar.
我们已经看到,使用k - means和类似的算法,决定集群的数量可能会很棘手. 与美联社, 我们不需要明确地指定它, 但是,如果我们获得的集群比我们可能找到的最优集群多或少,它可能仍然需要一些调优. 幸运的是,通过调整偏好,我们可以减少或增加集群的数量. 将首选项设置为更高的值将导致更多的集群, 因为每个点都“更确定”其作为范例的适用性,因此更难“击败”并将其纳入其他点的“统治”之下。. 相反, setting lower preferences will result in having less clusters; as if they’re saying “no, no, 请, 你是个更好的榜样, 我会加入你的团队。”. 一般来说, 我们可以将所有偏好设置为中等到大量集群的中位数相似度, 或者在中等数量的集群中达到最低的相似度. 然而, 为了得到完全符合我们需要的结果,可能需要几次调整偏好的运行.
分层亲和传播也值得一提, 作为该算法的一种变体,它通过将数据集分成几个子集来处理二次复杂度, 将它们分开聚类, 然后执行第二级聚类.
有一系列的聚类算法, 每一个都有它的优点和缺点,关于什么类型的数据, 时间复杂度, 弱点, 等等......。. 提到更多的算法, 例如,有层次聚集聚类(或连锁聚类), 当我们不一定有圆形(或超球形)集群时,这很有用, 而且事先不知道集群的数量. 开始时,每个点都是一个单独的簇, 它的工作原理是在每一步中连接两个最接近的集群,直到所有的东西都在一个大集群中.
与 分层凝聚聚类, 我们可以很容易地决定集群的数量,然后通过水平切割树形图(树形图),我们发现合适的地方. 它也是可重复的(总是给出相同的数据集相同的答案), 但也有更高的复杂度(二次).

然后, DBSCAN (Density-Based Spatial Clustering of Applications with Noise)也是一个值得一提的算法. 它将紧密排列在一起的点分组, 在任何有邻近点的方向上扩展星团, 因此处理不同形状的簇.
这些算法值得专门写一篇文章, 我们可以在后面的单独帖子中探索它们.
It 需要经验 通过一些试验和错误来知道何时使用一种算法或另一种算法. 幸运的是, 我们有一系列不同编程语言的实现, 所以尝试它们只需要一点点意愿.
世界级的文章,每周发一次.
世界级的文章,每周发一次.



 作者都是各自领域经过审查的专家,并撰写他们有经验的主题. 我们所有的内容都经过同行评审,并由同一领域的Toptal专家验证.
作者都是各自领域经过审查的专家,并撰写他们有经验的主题. 我们所有的内容都经过同行评审,并由同一领域的Toptal专家验证.